

5 月 6 日晚間, IBM (IBM-US) 在全球科技企業的製程大戰中,率先突破了 3 nm 的極限,成功推出了全球首款採用 2nm 工藝的晶片,雖然這只是實驗性質的項目,但是根據 IBM 的材料來看,這款 晶片每平方毫米可容納 3.33 億個電晶體,而作為對比目前最先進的台積電( 2330-TW ) 5nm 工藝每平方毫米最多才能2nm容納 1.713 億個電晶體,而三星 5nm 工藝每平方毫米最多只能容納 1.27 億個電晶體。
IBM 這次最大的突破性進展是將 FET 工藝的樣片帶到大眾面前,本文後面也會介紹 GAAFET 將是矽基半導體突破 FinFET 工藝 5nm 極限的關鍵技術。本次 IBM 的 GAAFET 採用了 75nm 的單元高度, 40nm 的單元寬度,單個奈米片的高度為 5nm ,彼此之間間隔 5nm 。閘極間距為 44nm ,閘極長度為 12nm ,其底部採用介電隔離通道、內部的間隔器採用第二代乾式工藝的開創性方案。
同時 IBM 也官宣了這款晶片的性能指標,其中與目前主流的 7nm 晶片相比,這款晶片的性能預計提升 45% ,能耗降低 75% 。而與 5nm 晶片相比, 2nm 晶片的體積更小,速度更快。與 7nm 的經典之作蘋果(Apple, AAPL-US) A12 相比, 5nm 的蘋果 M1 性能提升近 100% ,能耗也低了 50% ,也就是說這款 2nm 的 GAAFET 晶片並沒有形成對於蘋果 M1 的碾壓效果,可見 7nm 以下提升製程工藝的效益已經沒有那麼明顯了。
一、為什麼是製程
上世紀 40 年代由美國發起的曼哈頓計劃,不但為人類帶來了原子彈,也為我們帶來了電腦,IT 產業發展至今已經形成了數十兆美元的巨大產業,如果說 IT 產業的明珠是晶片,那麼晶片產業的皇冠就是晶圓製造,而晶圓製造的關鍵又在於製造。
這裡也再為大家科普一下製程的相關概念,在上世紀 60 年代,仙童半導體創辦人之一摩爾在《電子學》雜誌上發表論文,提出了至今仍有巨大影響的摩爾定律,即當價格不變時,積體電路上可以容納的元器件的數目,將每隔一年增加一倍,這其實就是指原件的密度會不斷增大,也就是元件之間的間隔距離不斷減少,而在晶片中不同元件的距離就是製程,所以摩爾定律也可以被稱為是製程定律。
在不斷縮減晶片中電晶體的距離之後,電晶體之間的電容會更低,電晶體的開關頻率也會更高。由於電晶體在切換高低電平時動態功率與電容成正比,製程低的晶片可以做到速度快的同時,還能更加省電、更加節能。同時體積越小電晶體的導通電壓也就越低,而動態功耗又與電壓的平方成反比,這時單位面積能效比也會隨之提升。
在 10nm 工藝之前,提升製程幾乎是提升晶片性能的代名詞,比如 10nm 驍龍 835 體積比 14nm 驍龍 820 還要小了 35% ,整體功耗降低了 40% ,性能卻大漲 27% 。因此我們可以看到晶片最大的宣傳點往往就是它的製程。
二、晶片的三大時代
正如前文所說本次 IBM 的 2nm 晶片關鍵性突破就在於為 IT 界帶來了真正意義上的 GAAFET 樣片,在 GAA 之前半導體的製作工藝主要有 MOS 和 FinFET 兩個重要的時代:
MOS 時代:在上世紀 50 年代末貝爾實驗室研製出 MOS 管,也就是金屬氧化物半導體場效電晶體,隨著 MOS 管的推出,電腦的電子管時代正式結束,在 MOS 管推出不久後,量產電晶體的平面工藝誕生,這項工藝可以通過氧化、光刻、等一系列的流程,製作出成規模的電晶體積體電路,這也就是我們目前晶片的雛形。不過隨著元件密度的不斷加大, MOS 管製程限制的劣勢也就顯現出來了。
FinFET 時代:由於 MOS 管並不盡善盡美,並且其製程存在著 20nm 的極限,業界一直探索著半導體製造工藝的前進方向,不過 MOS 管始終保持著強大的生命力,IT 業一直探索到 2000 年,才由加州大學伯克利分校的胡正明教授找到 FinFET 的方式,當時胡正明教授發表題為《 FinFET-a self-aligned double-gate MOS FET scalable to 20 nm》的論文,並在論文中提出了一種名為“鰭式場效電晶體”也就是 FinFET 的電晶體結構,顧名思義 FinFET 的結構形狀類似於魚鰭。
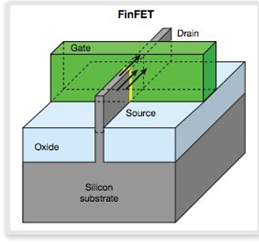
▲FinFET 使得晶片製程突破了 20nm 的工藝關鍵節點,是推動當代工藝進一步縮小的關鍵技術。
未來的 GAAFET 時代: GAA 也就是 Gate-All-Around,是由Imec提出的。 GAA 的技術特點是實現了閘極對溝道的四面包裹,源極和漏極不再和基底接觸,而是利用線狀或者平板狀、片狀等多個源極和漏極橫向垂直於閘極分佈後,實現 MOS FET 的基本結構和功能。這樣的設計在大幅解決閘極間距尺寸減小後帶來的各種問題,包括電容效應等,也可以突破目前 5nm 的製程極限,不過從目前 IBM 2nm 晶片的情況來看,這項技術距離正式商用恐怕還有很長的路要走,並且即使突破 5nm ,也很難對於 FinFET 結構的晶片產生代差優勢。
三、AI 優化:英特爾和 ARM 都在押注的方向
在紛亂的製程之爭背後,我們也需要仔細觀察其它半導體巨頭的發展方向,最近英特爾(Intel, INTC-US)的至強三代和安謀推出的 ARM v9 似乎都把大招留給了專為優化矩陣運算而設計的 SIMD 技術。
我們看到帕特・基辛格正式回歸英特爾之後最新的至強三代推出 Ice Lake-SP 晶片,並隨之推出了AVX- 512 與 VNNI 兩種AI 運算加速技術,還有前不久 ARM v9 上的 SVE2 ,從本質上來說它們都屬於 SIMD 技術,而 SIMD 的由來要從晶片收入線技術聊起,我們知道 CPU 的每個動作都需要用晶體震盪而觸發,以加法 ADD 指令為例,想完成這個執行指令需要取指、譯碼、取操作數、執行以及取操作結果等若干步驟,而每個步驟都需要一次晶體震盪才能推進,因此在收入線技術出現之前執行一條指令至少需要 5 到 6 次晶體震盪週期才能完成。
為了縮短指令執行的晶體震盪週期,晶片設計人員參考了工廠收入線機制的提出了指令收入線的想法。由於取指、譯碼這些模組其實在晶片內部都是獨立的,完全可以在同一時刻並發執行,那麼只要將多條指令的不同步驟放在同一時刻執行,比如指令 1 取指,指令 2 譯碼,指令 3 取操作數等等,就可以大幅提高 CPU 執行效率:
以上圖收入線為例,在 T5 時刻之前指令收入線以每週期一條的速度不斷建立,在 T5 時代以後每個震盪週期,都可以有一條指令取結果,平均每條指令就只需要一個震盪週期就可以完成。這種收入線設計也就大幅提升了 CPU 的運算速度。
SIMD (Single Instruction Multiple Data)也就是單指令多數據流技術,其實就是一種數據收入線的技術,我們知道在 AI 神經網路世界中操作數可能很長,以深度神經網路為例,神經元可以抽象為對於輸入數據乘以權重以表示訊號強度乘積加總,再由ReLU、Sigmoid等應用啟動函數調節,本質是將輸入數據與權重矩陣相乘,並輸入啟動函數,對於有三個輸入數據和兩個全連接神經元的單層神經網路而言,需要把輸入和權重進行六次相乘,並得出兩組乘積之和。這實際上就是一個矩陣乘法運算。而一個操作數往往只能表示矩陣中的一個元素,這也使得傳統 CPU 在進行矩陣運算時效率很低。
而英特爾的 VNNI (Vector Neural Network Intruction)和 ARM v9 的 SVE2 恰恰都是支持變長輸入的指令集。
讀者們可把這項技術簡單理解為在一個週期內可以將指令所需的所有操作數全部取到,而且讀操作數的個數還是可變長的,這樣矩陣運算的效率就可以大大提升。目前 ARM v9 晶片還沒有產品發布,而至強三代的處理器已有推出一段時間了,從筆者了解到的情況看,可變長的 VNNI 在騰訊應用時,可以使 2D 轉 3D 的建模速度提升 4.24 倍以上,這意味著原有基於 3D 人臉建模比較慢的各種優化、緩存、預處理都不需要了,在大部分場景當中騰訊都能為遊戲玩家提供所見即所得的 3D 頭像。
總而言之我們這次的好消息是 GAAFET 並沒有強到能與現有 FinFET 工藝拉開代差的地步,同時我們也要體認到半導體領域更具有基礎科學的屬性,只能硬碰硬,沒有捷徑可言。
《虎嗅網》授權轉載
【延伸閱讀】