

前篇引導:數據分析專題(二):從儲存、挖掘到溝通,引領產業新面貌:大數據(Big Data)
從Google Alphago到Chatbot聊天機器人、智慧理專、精準醫療、機器翻譯… 近年來時而聽到人工智慧、機器學習的相關消息,一夕之間這項技術攻占了各大媒體版面。不但Google、Facebook、微軟(Microsoft, MSFT-US)、百度(Baidu, BIDU-US)、IBM等巨頭紛紛進軍該領域,NVIDIA執行長黃仁勳亦宣稱將由顯示卡轉型成人工智慧運算公司,強調人工智慧浪潮的來臨。
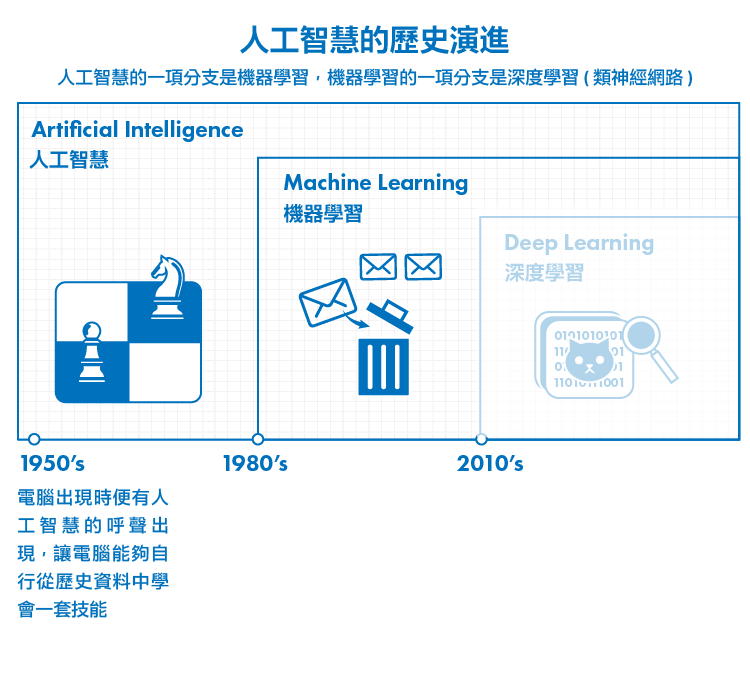
機器學習是人工智慧的一個分支。然而什麼是人工智慧?什麼是機器學習?要解決的又是什麼問題呢?今天就讓我們來聊聊,未來十年內將會真正改變你我生活的新世代技術。
人工智慧: 如何以電腦解決問題
人類自從發明電腦以來,便始終渴望著能讓電腦擁有類似人類的智慧。一提到人工智慧,很容易令人想到電影與科幻小說中常見會聊天、會煮飯還會突然間想毀滅人類取而代之的機器人形象。
究竟什麼算作「智慧」?若電腦能針對我們的問題準確地作回答、或學會下棋和泡咖啡,如此就能確定電腦擁有智慧嗎?要怎麼確定它真正擁有意識、理解情感?
當年AI技術尚未真正發展起來,哲學家與人文學家已就這個問題做過許多廣泛的討論。根據這個問題,美國哲學家約翰.瑟爾(John Searle)便提出了「強人工智慧」(Strong A.I.)和「弱人工智慧」(Weak A.I.) 的分類,主張兩種應區別開來。
強人工智慧受到電影與科幻小說的影響,強調電腦將能擁有自覺意識、性格、情感、知覺、社交等人類的特徵。另一方面,弱人工智慧主張機器只能模擬人類具有思維的行為表現,而不是真正懂得思考。他們認為機器僅能模擬人類,並不具意識、也不理解動作本身的意義。簡單來說,若有一隻鸚鵡被訓練到能回答人類所有的問題,並不代表鸚鵡本身瞭解問題本身與答案的意義。
在著名的圖靈測試中,如果一台機器與人類對話、而不被辨別出己方的機器身分時,便能宣稱該機器擁有智慧。這可以算是人工智慧的一種檢測方式,然而,強人工智慧擁護者可能會反駁──表現出「智慧」的行為不代表它真正擁有智慧、瞭解對話的意義。
當然弱人工智慧擁護者也可以反駁──我們永遠不可能知道另一個人的想法,比如我在和一個人對話時,並不知道對方是否和我進行一樣的思考方式,因此我們不能否定這台機器存在智慧的可能。是否有點類似莊子和惠子的子非魚安知魚之樂的對話呢?
有興趣的讀者能再就上述問題持續深入討論思考。不過在電腦科學界,直至目前為止尚不須深入糾結在這個問題層面。電腦科學家在意的是──我們能用人工智慧解決什麼樣的問題。
1950年代的電腦科學方起步,從科學家到一般大眾都對於電腦充滿無盡的想像,不但從大導演弗裡茨·朗的大都會到作家艾西莫夫的機器人三大法則,主流科學界也都預估約莫20到30年左右的時間便可以成功創造出與人類智能同樣高度的人工智慧。
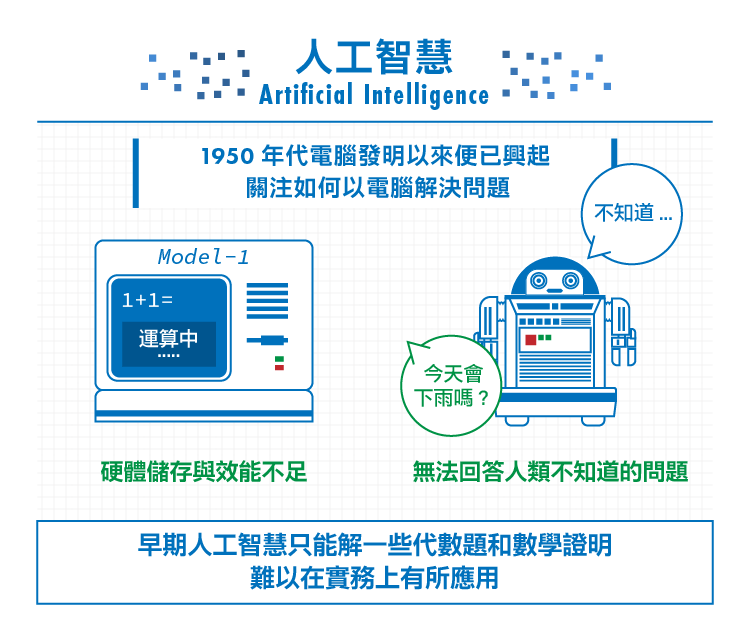
然而,人工智慧的研究很快便面臨了瓶頸──機器程序是由人類撰寫出來的,當人類不知道一個問題的解答時,機器同樣不能解決人類無法回答的問題。另一個問題是,當時電腦的計算速度尚未提升、儲存空間也小、數據量更不足夠,硬體環境上的困境使早期人工智慧只能解一些代數題和數學證明,難以在實務上有所應用。
在1970到1980年末時,一些知名研發計畫如紐厄爾和西蒙的「通用問題求解器」和日本政府領頭的「第五代電腦系統」達不到預期效果時,人工智慧開始被人們視為一場現代煉金術,企業與政府紛紛撤資、研究基金被削減、多個計畫被停止。此時迎來了人工智慧的第一場寒冬期。
雖然此時人工智慧的研究邁入了瓶頸,但是電腦硬體卻是以指數型的方式進步。1965年Intel創始人摩爾觀察到半導體晶片上的電晶體每一年都能翻一倍;到了 1975 年,這個速度調整成每兩年增加一倍,電腦的運算能力與儲存能力同時跟著摩爾定律高速增漲。如今,電腦的運算能力約為30年前的100萬倍。
早期的人工智慧研究聚焦在邏輯推論的方法,專注於模仿人類推理過程的思考模式。由於需要百分之百確定的事實配合,因此在實務上不容易使用。
直到關於人工智慧的研究方向越來越多元,涵蓋了包括統計學、機率論、逼近論、博弈論等多門領域的學科;而硬體儲存成本下降、運算能力增強,加上海量數據,今日的人工智慧已能從資料中自行學習出規律,這便是時下資料科學的最熱門技術「機器學習」。
機器學習: 從資料中自行學會技能
機器學習是實現人工智慧的其中一種方式。傳統上實現人工智慧的方式需要人們將規則嵌入到系統,機器學習(Machine Learning) 則是讓電腦能夠自行從歷史資料中學會一套技能、並能逐步完善精進該項技能。
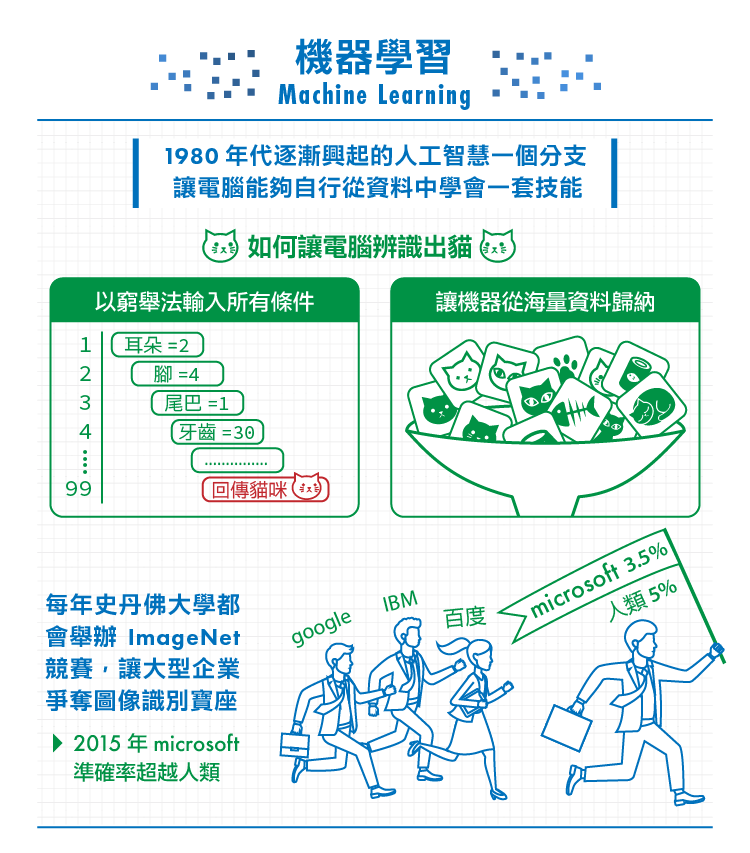
什麼技能呢?舉例來說,辨識貓咪的技能。
人類是如何學會辨識一隻貓的?我們不是熟背所有貓的詳細特徵:「尖耳朵、四肢腳、有鬍子、體型、毛色、…」從短毛貓、摺耳貓、短毛貓、暹羅貓…等貓咪的外型特徵都不一樣,甚至要將老虎、花豹等類似貓但不是貓的照片排除出來。
一般只要父母帶小孩看看貓、或貓咪的圖片,只要看到就告訴孩子這是貓,當小孩把老虎看成貓時進行糾正,久而久之,我們就自然地「學」會辨識一隻貓了。雖然不是原本看過的貓咪,我們仍然知道這是一隻貓。
從前讓電腦辨識出貓時,需要工程師將所有貓的特徵以窮舉法的方式、詳細輸入所有貓的可能條件,比如貓有圓臉、鬍子、肉肉的身體、尖耳朵和一條長尾巴;然而凡事總有例外,若我們在照片中遇到了一隻仰躺只露出肚子的貓?正在奔跑炸毛的貓?尖臉短尾貓?也因此誤判的機率很高。
美國普林斯頓大學李飛飛與李凱教授在2007年合作開啟了一個名為「ImageNet」的專案,他們下載了數以百萬計的照片、處理並分門別類標示好,供機器從圖像資料中進行學習。如今,ImageNet已是全世界最大的圖像識別資料庫,光是「貓」便有超過六萬兩千種不同外觀和姿勢的貓咪,同時有家貓也有野貓、橫跨不同的種類。每年,史丹佛大學都會舉辦ImageNet圖像識別競賽,參加者包括了Google、微軟、百度等大型企業,除了在比賽中爭奪圖像識別寶座、同時測試自家系統的效能與極限。如今的機器從海量資料中學習後,能辨別出的不僅僅只有貓了,從路燈、吊橋、奔跑的人、狗狗… 電腦終於學會如何「看」這個世界。
究竟機器是怎麼從資料中學會技能的呢?為了瞭解機器學習是如何從資料中學習,獲得辨識或預測新進資料的技能,首先來為大家介紹一個經典的入門主題:「分類」(Classification)。
到深山裡遊玩卻不小心落難、肚子飢餓難耐時總會忍不住想要採路邊的野菇吃。然而有一些菇類看似樸素卻可能有毒、有些菇類色彩豔麗卻能食用;如何讓電腦幫助我們判別有毒的菇種、在野外成功存活下來呢?
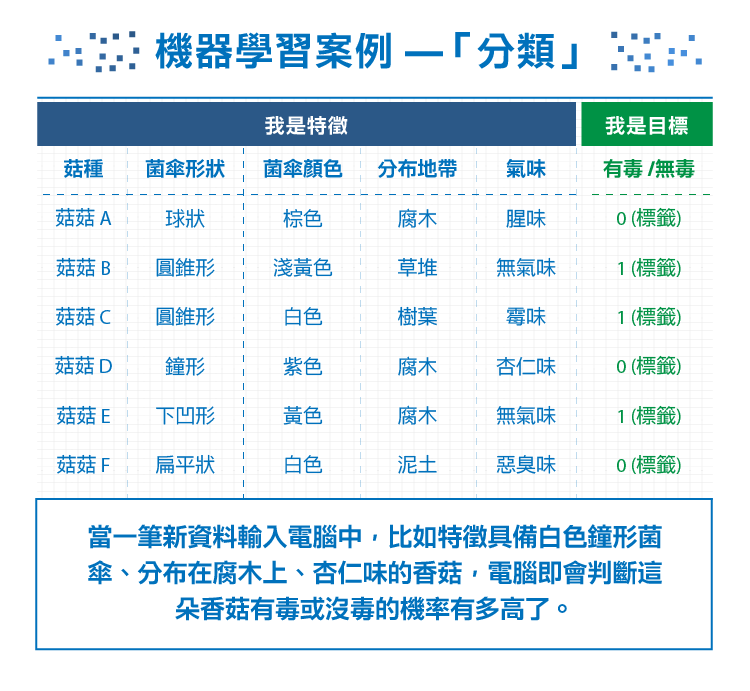
為了訓練機器,我們先蒐集了有毒菌菇和無毒菌菇的資料樣本、作為訓練資料(Training Data)。從訓練資料中擷取出資料的特徵(Features) 幫助我們判讀出目標,比如菌傘形狀、顏色,菌炳形狀、顏色,菌環數量,分布地帶,氣味… 再告訴電腦每一個菌菇所對應到的答案──把有毒菌菇的資料標籤(Label)為1、無毒的菌菇標籤為0,由此讓電腦知道哪些菇有毒、哪些菇沒毒。
隨著訓練的資料量夠大時,當一筆新資料輸入電腦中,比如特徵具備白色鐘形菌傘、分布在腐木上、杏仁味的香菇,電腦即會判斷這朵香菇有沒有毒、有毒或沒毒的機率有多高了。 (由於筆者非菇類學家,此僅為舉例,請勿深究本文中如何判別有毒菇類的真實性。)
除此之外,我們也可從過去的天氣資料中、找出有下雨的天氣特徵,並在進來一個新的天氣情境資料時能預測下雨的機率,以進行氣象預測。甚至是垃圾郵件過濾 (判斷要不要把郵件丟到垃圾桶)、股市漲跌 (判斷特定情境下這檔股票會漲會跌)、醫療病徵判斷 (判斷有了這些症狀後,患者有得病沒得病)… 各產業領域皆可應用機器學習技術。
訓練機器學習模型時,技術上有哪些重要的部分呢?
- 資料清整 (Data Cleaning):
機器既然得從海量資料中挖掘出規律,「乾淨」的數據在分析時便非常地關鍵。在分析的一開始時,得處理資料的格式不一致、缺失值、無效值等異常狀況,並視資料分佈狀態,決定如何填入資料,或移除欄位,確保不把錯誤和偏差的資料帶入到資料分析的過程中去。
- 特徵萃取 (Feature Extraction)與特徵選擇 (Feature Selection)
特徵萃取 (Feature Extraction)是從資料中挖出可以用的特徵,比如每個會員的性別、年齡、消費金額等;再把特徵量化、如性別可以變成0或1,如此以來每個會員都可以變成一個多維度的向量。
經過特整萃取後,特徵選擇 (Feature Selection)根據機器學習模型學習的結果,去看什麼樣的特稱是比較重要的。若是要分析潛在客戶的話,那麼該客戶的消費頻率、歷年消費金額…等可能都是比較重要的特徵,而性別和年齡的影響可能便不會那麼顯著。藉由逐步測試、或使用演算法篩選特徵,找出最恰當的特徵組合讓學習的效果最好。
- 模型選取
資料科學家會根據所要解決的問題、擁有的資料類型和過適化等情況進行衡量評估,選擇性能合適的機器學習模型。由於機器學習模型的數量與方法非常多,包括了神經網路、隨機森林、SVM、決策樹、集群….。以下僅將機器學習模型依據幾種常見的問題類別進行介紹。
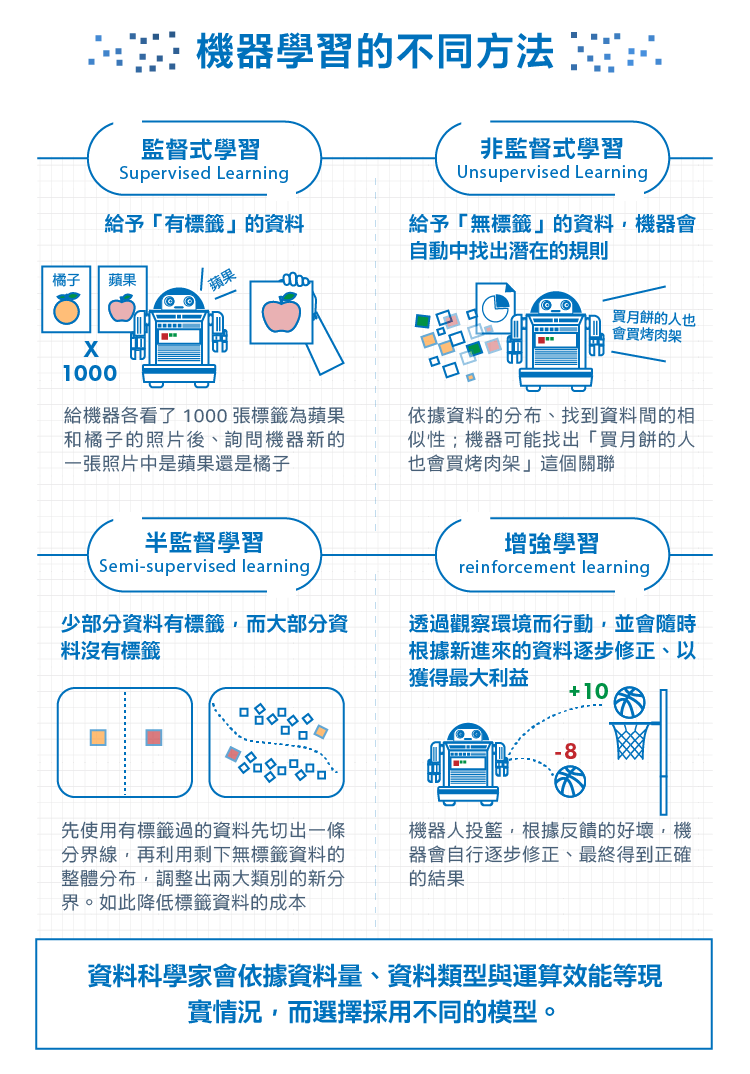
在先前的段落中,我們介紹了預先把有毒菇類的資料標籤 (Label)為1、沒有毒的菇類資料標籤為0,讓機器學會辨識有毒菇的方法,事實上叫做「監督式學習」,除此之外還有「非監督式學習」:
- 監督式學習 (Supervised Learning): 在訓練的過程中告訴機器答案,也就是「有標籤」的資料,比如給機器各看了1000張蘋果(Apple, AAPL-US)和橘子的照片後,詢問機器新的一張照片中是蘋果還是橘子。
- 非監督式學習 (Unsupervised Learning): 訓練資料沒有標準答案、不需要事先以人力輸入標籤,故機器在學習時並不知道其分類結果是否正確。訓練時僅須對機器提供輸入範例,它會自動從這些範例中找出潛在的規則。
簡單來說,若輸入資料有標籤,即為監督式學習;資料沒標籤、讓機器自行摸索出資料規律的則為非監督式學習,如集群 (Clustering)演算法。
非監督式學習本身沒有標籤(Label)的特點使其難以得到如監督式一樣近乎完美的結果。就像兩個學生一起準備考試,一個人做的練習題都有答案(有標籤)、另一個人的練習題則都沒有答案,想當然爾正式考試時,第一個學生容易考的比第二個人好。
另外一個問題在於不知道特徵 (Feature)的重要性──比如說演算法「集群」(Clustering),給機器一個1000名的顧客資料表 (含性別、生日、職業、教育…),機器會自動爬梳出隱含的資料規律將這1000人分群。其主要目的在於找出比較相似的資料聚集在一起,形成集群(Cluster);而相似性的依據是採用「距離」,相對距離愈近、相似程度越高,被歸類至同一群組。
但顯然一定會有一些特徵 (Feature)其實不是很重要,但因為分布比較可以拉開距離,所以機器在分群的時候會傾向用它來分,導致需要以人工再自行調整這些東西,不然一定會做出莫名其妙的結果。這邊需要澄清的事情是,並不是要篩選掉特徵 (Feature),每一個特徵 (Feature)都有它的意義,我們要做的只是要降低它的重要性。
矛盾的是,人工很難訂出各特徵 (Feature)的重要性或是距離的意義等,若人工有辦法定義和介入,為什麼還會需要集群這個演算法呢?故由於分群時沒有足夠的線索知道各個特徵 (Feature)的重要性,因此很容易對某些分布的特徵 (Feature)產生偏誤、造成無意義的分群結果。
非監督式學習在應用上不若監督式學習廣泛,但非監督式學習在資料探勘初期時,可被用來探索龐大的客戶群中存在哪些自然群體,而這些群體可能又能轉而提示我們其他的資料分析方法。
除了集群外,常見的非監督式學習尚包括關聯規則探索(Association Rule Discovery)、或稱共生分群(co-occurrence grouping),找出資料發生的關聯性。集群是依據資料的分布、找到資料間的相似性;而關聯規則則是以資料一起出現的情況、來考量資料的相似性,例如在分析超市的購物紀錄時,我們可能會發現「買月餅的人也會買烤肉架」。
針對這樣的發現該如何採取行動需要行銷人員再深入挖掘原因,不過基本上已暗示了可舉辦的促銷活動或優惠套餐組合。商品購買方面的關聯規則稱為購物籃分析,除此之外關聯規則如今還被應用在異常檢測上,比如有人突然入侵你的Email帳號時。
這時你可能會想,難道監督式學習和非監督式學習就是彼此涇渭分明?在實際應用中,將大量的資料一一進行標籤是即為耗費人工的事情,最常見的狀況是──少部分資料有標籤,而大部分資料沒有標籤、且數量遠大於有標籤的資料。畢竟要標籤資料費時費力、蒐集無標籤的資料更快速方便。這時候我們可以採用:
- 半監督學習 (Semi-supervised learning):介於監督學習與非監督學習之間。
以下是半監督學習的簡單示意。在將資料分群的過程當中,先使用有標籤過的資料先切出一條分界線,再利用剩下無標籤資料的整體分布,調整出兩大類別的新分界。如此不但具有非監督式學習高自動化的優點,又能降低標籤資料的成本。
前面我們提到監督式學習在面對一個指定問題時,可以明確告訴你正確的答案是什麼,比如今天會下雨或不會下雨、或是這封信該不該丟到你的垃圾郵件匣。
但遇到某些需要連續做決策的情況時,答案就不是一步就能解決了。比如下棋需要根據對手的攻勢隨時改變策略、或是開車會遇到的不同路況,為了達到贏棋或者通過山路的最終目的,必須因應環境的變動、隨之改變原有的作法。這時候我們就需要利用:
- 增強學習 (reinforcement learning):透過觀察環境而行動,並會隨時根據新進來的資料逐步修正、以獲得最大利益。
強化學習的一個經典理論「馬可夫決策過程」(Markov Decision Process)有一個中心思想,叫「明天的世界只和今天有關、和昨天無關了。」(The future is independent of the past given the present.)
在馬可夫決策過程中,機器會進行一系列的動作;而每做一個動作、環境都會跟著發生變化。若環境的變化是離目標更接近、我們就會給予一個正向反饋(Positive Reward),比如當機器投籃時越來越接近籃框;若離目標更遠、則給予負向反饋(Negative Reward),比如賽車時機器越開越偏離跑道。雖然我們並沒有給予機器標籤資料,告訴它所採取的哪一步是正確、哪一步是錯誤的,但根據反饋的好壞,機器會自行逐步修正、最終得到正確的結果。
原則上無需考慮以前的狀態,當前狀態便已傳達出、所有能讓機器算出下一步最佳行動的資訊;簡單來說就是每一個事件只受到前一個事件的影響。打敗世界棋王的Google AlphaGo便是馬可夫假設一個成功的應用。
增強學習的機器學習方法當然還不僅止於此,多拉桿吃角子老虎機(Multi-armed Bandit) 亦是增強學習的知名理論。Bandit是一個簡化過的增強學習方法,最重要的目標只有探索(Explore)和採集(Exploit)的平衡。這是什麼意思呢?
假設一個國家中有十家餐廳,每家餐廳提供的餐點份量相當不均 (有些可能會偷工減料)。某天該國突然湧入很多難民、因為餐券補助有限的關係,總共只能吃一百次餐廳,希望最後能餵飽最多的人。
顯然如果要吃到最多的東西,我們必須盡快找到「提供最大份量」的餐廳然後一直吃它就好了 (其他黑心餐廳就不吃了)。如果把每家都吃一遍才確定份量最大的餐廳,會浪費掉太多餐券;然而若只吃了兩三家、就直接選比較高的一家一直吃,我們可能會漏掉真正提供最大份量的那一家餐廳。
解決Bandit問題的目標在於──有限的精力中,一部分精力會分配去探索未知的可能(explore)、一部分則利用已知最好的策略不斷採集(exploit),演算法會透過不斷新增的環境數據進行調整,在兩者間尋求平衡、將利益最大化。
這樣的應用有哪些呢?當一個網站能展示的資訊量有限、卻又不知道使用者喜歡的東西是什麼、該優先顯示哪些內容,才能有最高的點擊率時,我們可以透過增強學習隨時進行優化、最快達到客製化。無論是Google廣告、Facebook將你可能會最感興趣的好友PO文排序在上方、Amazon呈現你最有興趣的商品,或是網站上線後的A/B Test,都可以看到增強學習的蹤影。
今天,我們回顧了人工智慧和機器學習的由來,並介紹機器學習的基本名詞 (特徵、標籤) 與常見的機器學習類別 (監督、非監督、半監督與增強學習)。
機器學習是相當實務的一門學科,資料科學家的最終目標是找到最好解決問題的方法,會依據資料量、資料類型與運算效能等現實情況,而選擇採用不同的模型。
下篇,我們的時間軸將來到1980年代,看那時正要大放異彩的類神經網路(Artificial Neural Network),是如何在風口前被淺層機器學習(Shallowing Learning)所逆轉。如此急轉而下的經過,讓我們下回揭曉。
【延伸閱讀】
- 數據分析專題(一):引爆資料中心革命:雲端運算
- 數據分析專題(二):從儲存、挖掘到溝通,引領產業新面貌:大數據(Big Data)
- 數據分析專題(四):機器學習的衰頹興盛:從類神經網路到淺層學習
- 數據分析專題(五):類神經網路的復興:深度學習簡史
- 數據分析專題(六):神經網路的復興:重回風口的深度學習