

輝達(NVIDIA, NVDA-US) (NVIDIA) 的股價在 2016 年漲了 3 倍多,2017 年至今又漲了 80%,這麼大幅的上漲到底是對人工智慧概念的炒作,還是企業多年耕耘的厚積薄發?不想明白這個問題,投資人就不可能在股價的上下波動中做到堅定持有。
GPU 是什麼?和 CPU 有什麼不同
簡單來說, CPU 擅長的是通用邏輯的順序執行,而 GPU 擅長的是特定邏輯的並行計算。現在性能最強勁的 CPU 也只有幾十個核,而 GPU 卻可以輕鬆做到上萬個核。
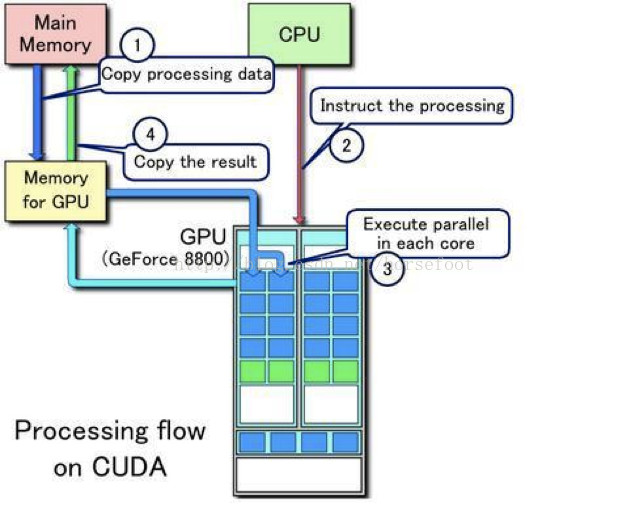
GPU 最早是用來做圖形渲染的,它可以並行的計算出各個像素點的值從而快速生成圖象,這個計算的本質就是四維向量和變換矩陣的乘法。後來人們發現不光是圖形渲染,很多計算任務,特別是現在火熱的深度學習,其本質也是矩陣運算,同樣也可以用 GPU 來加速計算過程。在實際的使用中,CPU 和 GPU 是配合使用的,程式的主體部分仍然由 CPU 執行,但 CPU 會將複雜的計算任務交給 GPU 來處理,如下圖所示。
“至於計算力,首先 GPU 不會替代 CPU ,它是攜手和 CPU 共同工作的,這也是我們為什麼把它稱之為加速器, CPU 是通用型的,什麼場景都可以適用。但是 GPU 在一些專門的問題上有非常大的能量。它的性能要比 CPU 超過 10 倍、50 倍甚至 100 倍。
因此,我們就認為最完美的架構是什麼呢?首先我們要有萬事皆能的 CPU ,再加上在某些重大計算挑戰方面非常有能力的 GPU ”
輝達在 AI 領域的競爭優勢到底是什麼?
要回答這個問題先得普及一下基本的電腦知識,就是程式到底是怎麼執行的。我們知道程式是用 C++、Java、python 這些程式語言寫出來的,這些都叫高級程式語言,特點是比較貼近自然語言,適合人去寫和理解,但是用高級語言寫出來的代碼 CPU 是理解不了的,是無法讓 CPU 直接運行的。
CPU 懂的語言叫指令集,這些指令集會直接操縱 CPU 的內部結構,比如寄存器,算術控制單元等等, CPU 指令集絶大多數的工程師都搞不懂,也不需要搞懂。我們有各種各樣的編譯器會幫我們把用高級語言寫出來的程式翻譯成 CPU 能懂的指令。
另外說一句,現在的桌面電腦和服務器 CPU 已經基本被 x86 指令集一統天下,所有的系統和軟體都是針對 x86 來編譯和開發的。而 x86 的專利基本上就是被英特爾(Intel, INTC-US) 和 AMD 牢牢的控制在手上,也就是說只有這兩家才能生產基於 x86 的 CPU 。
所以我們老是說為什麼生產不出來自己的 CPU ,這實際上是兩個問題,一個是晶片設計和工藝的問題,這個相對來說還好解決,只要堅持追趕總能慢慢縮小差距;另外一個就是 x86 的專利問題,要是英特爾和 AMD 不給你授權你就用不了。有人會說那我就自己搞一套指令集唄,這當然可以,其實也沒什麼技術難度,但問題是現有的所有的操作系統和軟體就會在你的 CPU 上跑不起來,因為不相容,那這樣誰又會來買你的 CPU 呢?
GPU 也是一樣的道理,要想讓你的代碼在 GPU 上跑起來,你就必須有一整套的代碼編寫,編譯和調試環境。輝達的 CUDA 就是這麼一套環境。 CUDA 的全稱是Compute Unified Device Architecture,統一計算設備架構。這個架構提供了一整套的C/C++程式接口,各種庫函數,runtime,底層驅動還有完善的技術支持文檔。而且,基於 CUDA 開發的程式只能跑在輝達的顯示卡上。
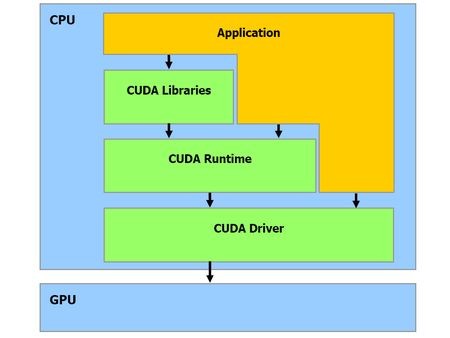
這就是輝達的過人之處,當 10 年前 AMD 還在和輝達拼顯示卡時, 輝達的研究員和工程師發現 GPU 稍作改造可以做很多科學計算相關的事情,於是發明了 CUDA 並且不斷投入完善,而當時沒有人做同樣的事情。 CUDA 相當於是建立了一個開發者社區,而且具有“網路效應”:
1. CUDA 具有越多人用越好用,越好用越多人用的正向反饋效應。因為用的人越多,輝達對用戶的需求和獲得的反饋也會越多,從而更好的改善產品性能。更重要的是,用戶在使用 CUDA 的過程中,會產生大量基於 CUDA 的入門文檔、研究成果、學術論文、開發類庫以及技術討論,這都極大的方便了後來加入的研究者。
CUDA 的開發人員在過去 5 年裡成長了 14 倍超過 60 萬; CUDA 下載量已達 180 萬,僅去年一年便增加了 80 萬。這可以看出整個 CUDA 社區還在壯大和蓬勃發展。
2. 用戶的遷移成本高。社交通訊軟體這類產品的黏性在於,你的整個社交關係鏈都在這個平台上。同樣,很多企業和研究人員之前的代碼,測試基準結果都是基於 CUDA 平台上的,一旦使用別的平台意味著代碼要重寫,重新編譯,之前的測試結果要重新校準,這都是非常高的成本。
AMD 的 GPU 能和輝達競爭嗎?
輝達的老對手 AMD 也推出了 Insinct 系列的 GPU 來和輝達在機器學習這塊競爭,在驅動和開發環境上, AMD 採用的是 OpenCL 。
就像上面提到的,CUDA 是輝達專有的,是一個封閉的體系,用了 CUDA 就意味著必須用輝達的顯示卡。而 OpenCL 是一個開放的標準,用其開發的程式可以跑在任何支持 OpenCL 標準的顯示卡上而不用和具體的硬體廠商綁定。
從通用性上來看,OpenCL 似乎是一個更好的選擇。但是 OpenCL 的致命弱點是其性能和開發的便利性都遠遠比不上 CUDA ,而且因為輝達在 CUDA 上投入了大量的人力財力其更新的速度飛快,OpenCL 作為一個開放鬆散的標準卻缺乏一個強有力的領導者來推動,兩者的差距還在拉大。
所以在機器學習這塊, AMD 已經無法撼動輝達的地位,只能做一個配角刷刷存在感。
兩週前,華爾街有家投行對輝達給出了 250 的目標價,這個數字可不可靠另當別論,當分析師在報告中對輝達競爭優勢的評價卻是非常的恰當:
簡單來說,因為先發優勢和累計 100 億美元的持續研發投入,CUDA 已經成為了一個生態系統和 AI 領域的行業標準,而這就是輝達豎起的競爭壁壘。
當然,這並不意味著輝達就可以高枕無憂了。壟斷者的威脅往往是來自於看不見的競爭對手和範式的變化。intel到現在為止都壟斷著基於 x86 的 CPU ,但手機晶片卻繞過了 x86 ,轉向了基於 ARM 的晶片,現在人工智慧又跑出來了個 GPU 。這就像你守住了一個路口,獲得了收過路費的壟斷經營權,結果隔壁老王又新修了一條路,人都不從你這過了。
我個人覺得在 GPU 這塊,已經沒有任何企業可以挑戰輝達了。但如果你注意 AI 領域新聞的話,經常會看到各種各樣其它的 xPU,比如 Google 的 TPU,還有什麼 DPU,最近英特爾還推出來了神經元晶片,號稱這才是人工智慧的未來。
那麼未來的計算範式會不會出現新的轉移呢?輝達的挑戰者會不會從別的地方冒出來呢?我覺得這些暫時還看不出來會帶來計算範式的轉變,但是值得持續的關注。而關注的重點不是在商業上的宣傳,而是在學術界和工業界的採用情況。
《雪球》授權轉載
【延伸閱讀】