

輝達(NVIDIA, NVDA-US),再次證明了自己獨一無二的存在。
作為全球 AI 產業毫無疑問的「賣鏟人」和「鋪路人」,輝達在今天淩晨召開的年度技術峰會 GTC 上再次展示了自己對於 AI 發展的「主權」。
簡單概括下來,主要包括三點:再次躍升的性能;強悍的生態控制力;迫近兌現時刻的創新潛力。三者相互結合,再次鞏固了輝達在 AI 時代的統治力。
最強晶片來襲!
 左側為全新的 B200 GPU,右側為 H200 GPU
左側為全新的 B200 GPU,右側為 H200 GPU
先說性能,在上一代 Hopper 架構發布兩年之後,輝達終於在這次 GTC 上發布了全新的 Blackwel l 架構。
從目前種種資訊,包括黃仁勳自己的發言來看,Blackwell 架構在計算模組上並沒有和 Hopper 存在很大差異,最大的不同在於輝達採用了類似蘋果(Apple, AAPL-US)M 系列處理器 Ultra的雙芯並聯設計,用新增加的超高速公路鏈路將兩顆晶片die通過晶片封裝的手段「組合」成了一顆大 GPU,從而讓全新的 B200 GPU 實現了單顆 GPU 2080 億晶體管的超大規模,再配合多達 192GB 的 HBM3e 顯存,讓 B200 GPU 直接成為了目前全球最強勁的 GPU 晶片。
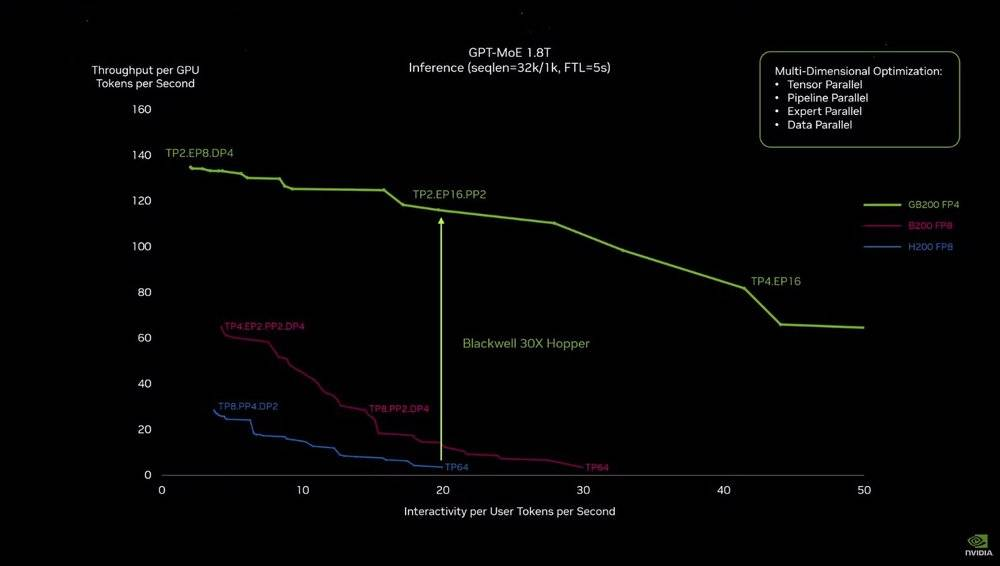 GB200 和上一代計算模組的性能曲線差距
GB200 和上一代計算模組的性能曲線差距
但在參數之外,其實際性能的提升卻要明顯的多:就拿大語言模型推理的實際應用場景來說,將兩個 Blackwell GPU 和一個 Grace CPU 結合在一起的 GB200 模組,能夠比上一代 H200 GPU 性能高足足 30 倍。
性能的提升,直接轉化為了功耗的下降,根據輝達官方給出的參考:同樣是在 90 天內訓練出GPT – MoE 1.8 兆參數模型,Hopper 架構的超級電腦需要 8,000 個 GPU 和 15 兆瓦的電力,而 Blackwell 只需要 2,000 個 GPU 和 4 兆瓦的電力。
 GB200 NVL72 機架
GB200 NVL72 機架
在明顯更集中的規模和更低的耗能之外,輝達還再次提升了他們晶片部署的解決方案:不僅將 GB200 模組設計為極其緊湊的堆疊結構,同時還配上了新一代直接讓 576 個 GPU 相互連接、雙向頻寬達到每秒 1.8TB 的 NVLink 交換機,結合 5,000 條近兩英里長的各種電纜,最終打造成為將 36 個 CPU 和 72 個 GPU 集成到一起的液冷機架。
這也是全球首個推理性能能夠超越 1exaflops 的電腦機架,同時也是比 GB200 更大的一顆「GPU」。
 GB200 DGX Superpod
GB200 DGX Superpod
而在這台超強機架的基礎上,輝達還能進一步擴大它的規模,拿被 GB200 「更新」的 DGX Superpod(輝達自己的超級電腦解決方案)來說,就由 8 套機架系統組成,總共擁有 288 個 CPU、 576 個 GPU、 240TB 內處理器和 11.5exaflops 的 FP4 計算能力。
這套系統最多還能進一步擴展至數萬顆 GB200 規模,這些充沛的算力,全部通過輝達自己的 800Gbps 網路設備連接在一起,形成更大規模的集群,也再次刷新了同類產品的性能上限。
黃仁勳在現場演講時就自豪地表示:「亞馬遜(Amazon, AMZN-US)、Google、微軟(Microsoft, MSFT-US)和甲骨文(Oracle, ORCL-US)都已計劃在其雲服務產品中提供基於 NVL72 機架的產品。」可以預見,國外的雲端運算即將刮起新一輪的輝達新 GPU 搶購潮。
充分發揮輝達優勢的新 AI 生態系統
早在 AI 還以自動駕駛為主旋律的時期,輝達就已經開始向車企客戶推廣其雲端服務解決方案。而為了滿足 AI 大模型時代的模型共享、模型定制化、模型運作、雲端運算支持在內的一系列問題,輝達在這次 GTC 上推出了全新的「輝達推理微服務(NIM)」。
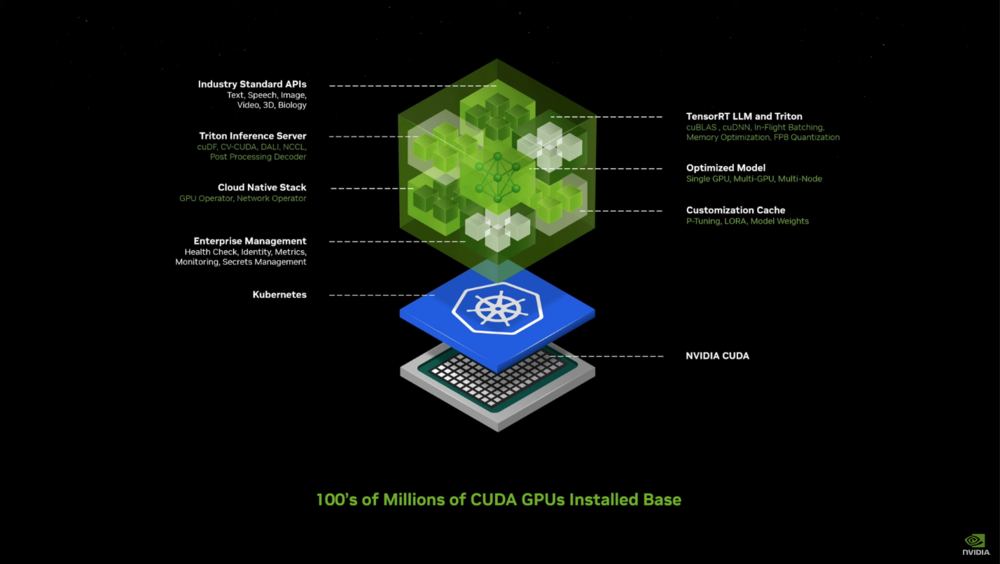 輝達推理微服務(NIM)
輝達推理微服務(NIM)
NIM 在構建的過程中,充分借鑒了 K8S (Kubernetes)這些年的成功經驗,將產業 API,AI 算法支持庫、雲端架構支持、AI 算法加速、定制模型、定制儲存、企業管理等訴求都注入到一個小的「容器」中,進而將 AI 模型的成果打包和部署過程高度簡化。
如果說容器化的理念已經很可怕,那麽更可怕的是這套解決方案,與目前 AI 產業智能體發展趨勢的契合度。
早在去年,在 ChatGPT 能力之上二次開發的 AutoGPT 就曾大火過一波,當時 AutoGPT 的策略是通過 ChatGPT 的多次循環,實現對複雜目標的拆分和分散尋找答案。但隨著後來的實踐,整個產業其實已經看到了其能力的局限性——單靠語言大模型並不能解決所有問題。
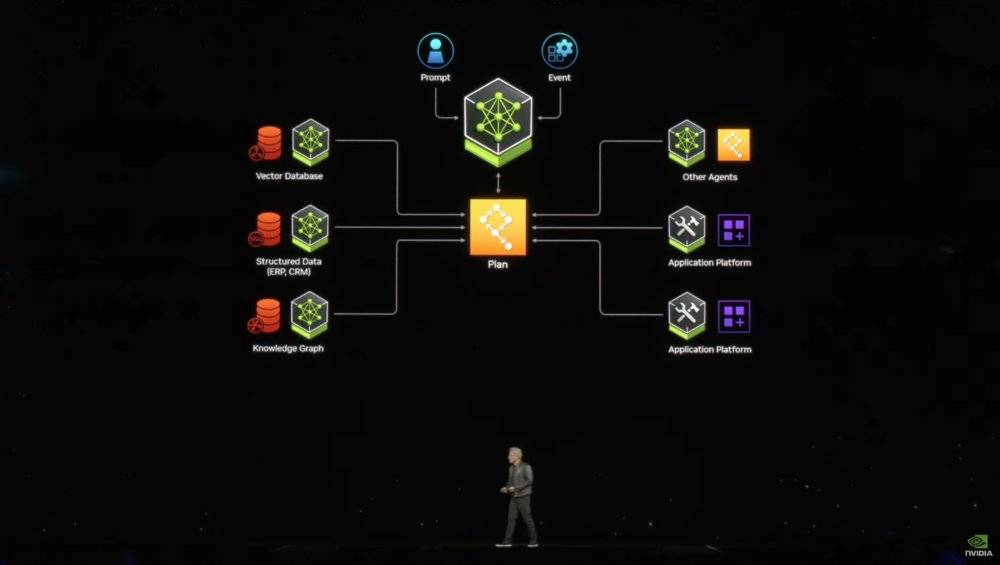 NIM 應用運作模式構想
NIM 應用運作模式構想
而目前產業內比較贊同的解決方案,就是在不斷提升基礎大模型能力的基礎上,不斷針對小的場景,提供專門的數據和目標,優化出解決一些問題的模型,也可以叫做「智能體」。通過這些「智能體」數量和覆蓋的累積,以及基礎大模型的調度能力,最終讓 AI 實現「自我計劃、自我協調」的進階人工智慧水平。更形象的說,就是一個輸入框解決用戶的絕大部分需求。
而持續為雲端提供充沛 AI 運作能力的輝達,顯然有推進這套機制的資本。
在有望加速全產業 AI 應用落地之余,輝達的這套 NIM 體系,還將把各種有潛力的 AI 模型和應用,緊緊地綁定在輝達有著明顯優勢的雲端算力性能和成本之上,進一步對抗由智慧型手機廠商發起的端側攻勢,讓其緊握遠期實現通用人工智慧(AGI)的先機。
根據輝達官方目前公布的計劃,NIM 體系將在 NVIDIA AI 企業版中首發,雖然 NIM 本身不收費,但是 NVIDIA AI 企業版收費不低,單 GPU 的使用權限包年就需要 4,500 美金,小時租金為 1 美元每小時。
迫近兌現、充滿潛力的其他應用創新
在本次 GTC 之上,除了晶片和硬體解決方案的更新,還有 AI 生態上的全新想法,輝達也按照慣例展開了幾個應用層面的創新案例。但如果你看過前幾年的 GTC,你肯定會覺得有點眼熟。
 數字孿生地球台風氣象模擬
數字孿生地球台風氣象模擬
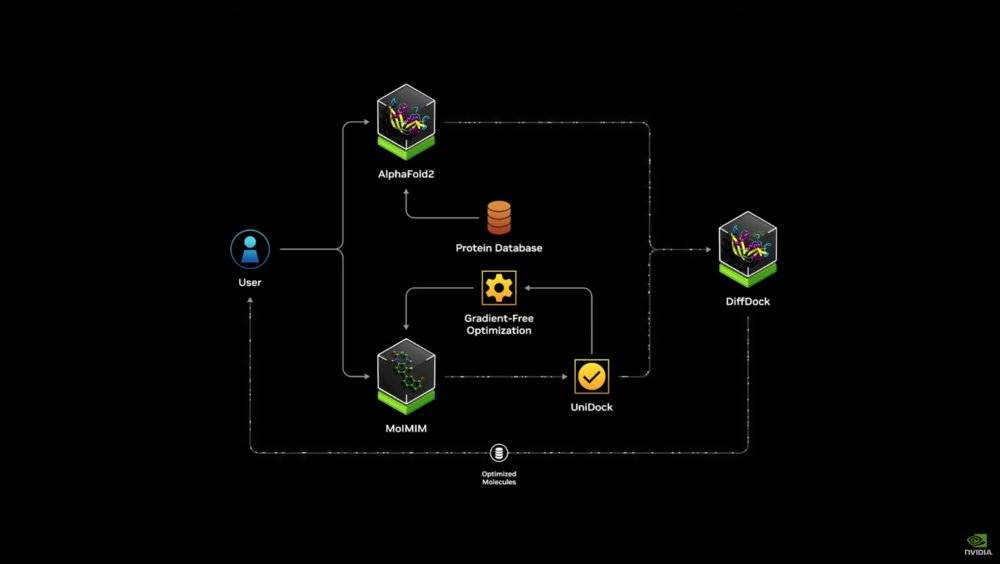 全新升級的蛋白質定制解決方案 DiffDock
全新升級的蛋白質定制解決方案 DiffDock
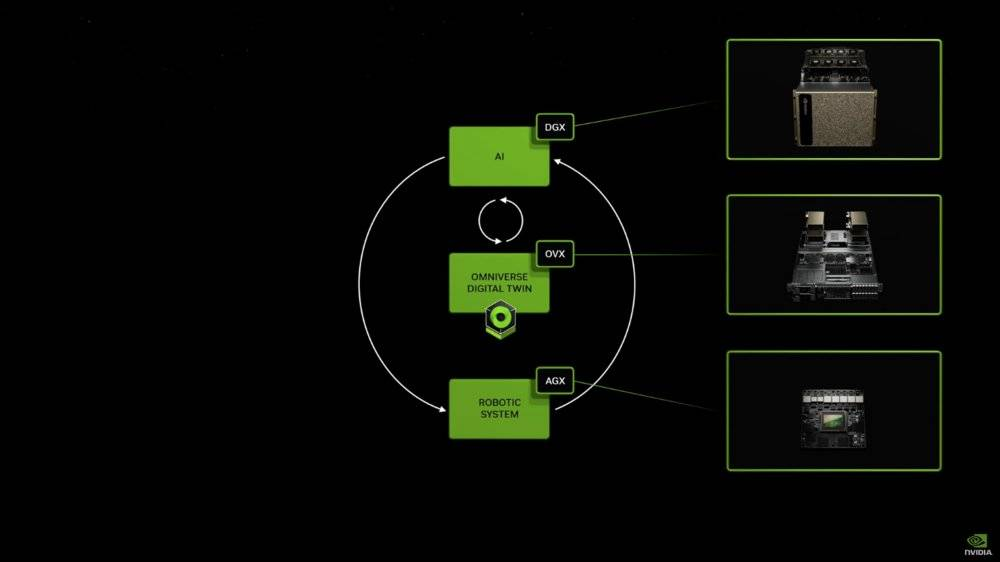 進一步由更強大計算能力和算法武裝的機器人/自動駕駛生態
進一步由更強大計算能力和算法武裝的機器人/自動駕駛生態
例如通過更大的 AI 算力,在更大的尺度上對全球的天氣進行學習預測,進而對台風等突發天氣實現 2 公里精度的即時預測;又比如已經探索了很多年的蛋白質折疊研究;還有機器人領域的全生態嘗試等等。
這些「舊」賽道在 AI 能力的提升下,其實都展現出了一定的新成果。
就拿機器人來說,輝達此次全新推出了人形機器人基礎模型 Project GR00T ,不僅可以通過人類的語言、影片和真實演示(感測器)來學習人類動作,還能夠在 GPU 模擬的虛擬世界中,通過 AI 的自我摸索來進行動作的訓練。
隨著 AI 集群的能力不斷提升,虛擬世界中的模擬複雜度已經從最早期的單機械手上升到人形機器人整體。很顯然,其實用價值也在隨著計算能力、AI 能力不斷躍升。
寫在最後
輝達之所以如此強大,主要體現在「遠見」之上。尤其是持續依靠「前端技術+下重注」引領全產業技術進步,持續享受到技術變革、產品變革的紅利。
就拿這次輝達全新打造的 GPU 來說,能夠如期更新,必然和輝達自己主動將 AI 應用於晶片研發製造流程中有著緊密的關聯。因為就在今天,台積電和新思科技(EDA 巨頭之一)已經宣布將使用輝達的計算光刻技術,通過集成的輝達 cuLitho 平台來加快晶片製造速度。
考慮到輝達針對未來的布局實在眾多,例如這次發表會上也被提到的「Earth Two」數字孿生地球項目,量子計算 SDK(軟體開發工具包)「cuQuantum」等,蛋白質定制研發工具Diffdock,人形機器人項目 Project GR00T , 6G 城市研究雲端平台等等。
這些技術變革帶來的紅利,仍將支撐輝達繼續坐穩全球 AI 產業,乃至整個科技產業的龍頭。
《虎嗅網》授權轉載
【延伸閱讀】
- Nvidia 輝達(NVDA)財報分析 2025 Q1!Q1 營收、Q2 財測超預期!
- Nvidia 輝達(NVDA)財報分析 2024 Q4
- AI 帶動散熱族群!散熱三雄獲利創高!散熱概念股還可以買?
- 2025 GTC 大會重點整理!全新晶片 Rubin 來了!黃仁勳說了什麼?